

 IoT s-a maturizat până la un punct în care puteți lansa cu încredere produse pentru a fi utilizate în teren, cu certificări precum PSA Certified™, care oferă garanția că IP-ul vostru poate fi securizat printr-o varietate de tehnici, cum ar fi motoare de securitate izolate, stocare securizată a cheilor criptografice sau utilizând Arm® TrustZone®. Astfel de asigurări pot fi găsite pe microcontrolerele (MCU) care au fost proiectate luând în considerare securitatea, dispunând de caracteristici de securitate scalabile bazate pe hardware, așa cum este familia RA de la Renesas. Cu toate acestea, adăugarea inteligenței artificiale conduce la apariția unor noi amenințări, care se infiltrează în zonele securizate și anume sub forma unor atacuri adversariale.
IoT s-a maturizat până la un punct în care puteți lansa cu încredere produse pentru a fi utilizate în teren, cu certificări precum PSA Certified™, care oferă garanția că IP-ul vostru poate fi securizat printr-o varietate de tehnici, cum ar fi motoare de securitate izolate, stocare securizată a cheilor criptografice sau utilizând Arm® TrustZone®. Astfel de asigurări pot fi găsite pe microcontrolerele (MCU) care au fost proiectate luând în considerare securitatea, dispunând de caracteristici de securitate scalabile bazate pe hardware, așa cum este familia RA de la Renesas. Cu toate acestea, adăugarea inteligenței artificiale conduce la apariția unor noi amenințări, care se infiltrează în zonele securizate și anume sub forma unor atacuri adversariale.
Atacurile adversariale vizează complexitatea modelelor de învățare profundă și matematica statistică subiacentă pentru a crea puncte slabe și a le exploata în teren, ceea ce duce la scurgeri de informații despre părți ale modelului, date de instruire sau la emiterea unor rezultate neașteptate. Acest lucru se datorează naturii de ‘cutie neagră’ a rețelelor neurale profunde (DNN), în care procesul decizional din DNN nu este transparent, adică sunt “straturi ascunse”, iar clienții nu sunt dispuși să își riște sistemele prin adăugarea unei caracteristici de inteligență artificială, ceea ce încetinește proliferarea inteligenței artificiale până la punctul final. Atacurile adversariale sunt diferite de atacurile cibernetice convenționale, deoarece în cazul amenințărilor tradiționale la adresa securității cibernetice, analiștii de securitate pot remedia o eroare (bug) în codul sursă și o pot documenta pe larg. Deoarece în DNN-uri nu există o linie specifică de coduri pe care să o puteți aborda, devine de înțeles că este dificil.
Atacurile adversariale în cultura pop pot fi văzute în Star Wars. În timpul războiului clonelor, Ordinul 66 poate fi văzut ca un atac adversarial, în care clonele s-au comportat așa cum era de așteptat pe tot parcursul războiului, dar odată ce au primit ordinul, s-au schimbat, determinând o răsturnare de situație în război.
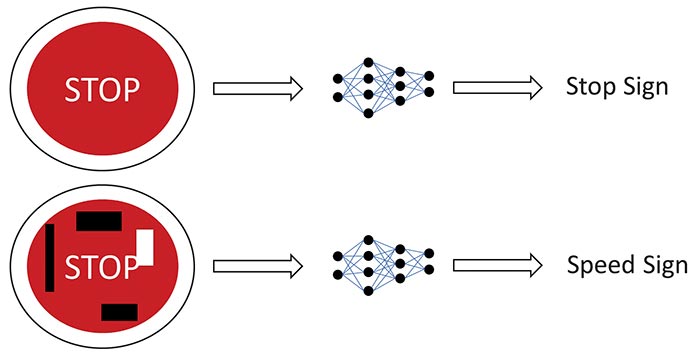
Figura 1: Autocolante lipite pe un indicator de circulație STOP pentru a înșela AI și a o face să creadă că este un indicator de viteză. (© Renesas)
Exemple notabile pot fi găsite de-a lungul a numeroase aplicații, cum ar fi o echipă de cercetători care a lipit autocolante pe indicatoarele de circulație STOP, determinând inteligența artificială să prezică faptul că este vorba despre indicatoare de viteză [1]. O astfel de clasificare greșită poate duce la accidente de circulație și la o mai mare neîncredere a publicului în utilizarea AI în sisteme. Cercetătorii au reușit să obțină o clasificare greșită de 100% în laborator și de 84,8% în testele din teren, demonstrând că autocolantele au fost destul de eficiente. Algoritmii păcăliți se bazau pe rețele neurale convoluționale (CNN), astfel încât proiectul poate fi extins la alte cazuri de utilizare care folosesc CNN ca bază, cum ar fi detectarea obiectelor și identificarea cuvintelor cheie.
Un alt exemplu dat de cercetătorii de la Universitatea din California, Berkley, a arătat că, prin adăugarea de zgomot sau perturbații în muzică sau în vorbire, modelul de inteligență artificială va interpreta greșit muzica redată sau va transcrie ceva complet diferit, deși perturbația respectivă este imperceptibilă pentru urechea umană [2]. Acest lucru poate fi utilizat cu rea intenție în cazul asistenților inteligenți sau al serviciilor de transcriere bazate pe inteligență artificială. Cercetătorii au reprodus forma de undă audio care este peste 99,9% similară cu fișierul audio original, dar pot transcrie orice fișier audio ales de ei cu o rată de succes de 100% pe algoritmul DeepSpeech de la Mozilla.
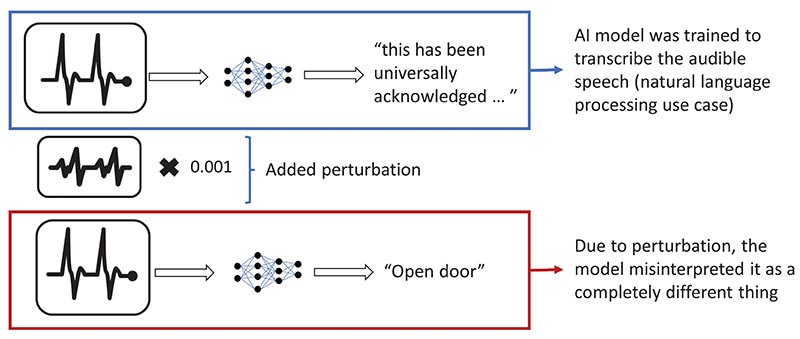
Figura 2: Prin adăugarea unei mici perturbații, modelul poate fi păcălit să transcrie orice frază dorită. (© Renesas)
Tipuri de atacuri adversariale
Pentru a înțelege numeroasele tipuri de atacuri adversariale, trebuie să ne uităm la pipeline-ul convențional de dezvoltare TinyML, așa cum este prezentat în figura 3. Inițial, instruirea se face offline, de obicei în cloud, urmată de executabilul binar final optimizat, care este plasat pe microcontroler și utilizat prin intermediul apelurilor API. Fluxul de lucru necesită un inginer specializat în aplicații de învățare automată și altul în aplicații embedded. Deoarece acești ingineri tind să lucreze în echipe separate, noul peisaj de securitate poate duce la confuzie în ceea ce privește împărțirea responsabilităților între diferitele părți interesate.
 Atacurile adversariale pot avea loc fie în fazele de instruire, fie în cele de inferență. În timpul instruirii, un atacator rău intenționat ar putea încerca “otrăvirea modelului”, care poate fi de tip direcționat sau nedirecționat. În cazul otrăvirii țintite a modelului, un atacator ar contamina setul de date de instruire/modelul de bază al AI, rezultând un “backdoor” (un tip de software rău intenționat) care poate fi activat de o intrare arbitrară pentru a obține o anumită ieșire, dar care funcționează corect cu intrările așteptate. Contaminarea ar putea fi o mică perturbare care nu afectează funcționarea așteptată (cum ar fi acuratețea modelului, viteza de inferență etc.) a modelului și ar da impresia că nu există probleme. De asemenea, acest lucru nu necesită ca atacatorul să ia și să implementeze o clonă a sistemului de instruire pentru a verifica funcționarea, deoarece sistemul însuși a fost contaminat și ar afecta ubicuu orice sistem care utilizează modelul/setul de date otrăvit. Acesta a fost atacul folosit asupra clonelor din Războiul Stelelor.
Atacurile adversariale pot avea loc fie în fazele de instruire, fie în cele de inferență. În timpul instruirii, un atacator rău intenționat ar putea încerca “otrăvirea modelului”, care poate fi de tip direcționat sau nedirecționat. În cazul otrăvirii țintite a modelului, un atacator ar contamina setul de date de instruire/modelul de bază al AI, rezultând un “backdoor” (un tip de software rău intenționat) care poate fi activat de o intrare arbitrară pentru a obține o anumită ieșire, dar care funcționează corect cu intrările așteptate. Contaminarea ar putea fi o mică perturbare care nu afectează funcționarea așteptată (cum ar fi acuratețea modelului, viteza de inferență etc.) a modelului și ar da impresia că nu există probleme. De asemenea, acest lucru nu necesită ca atacatorul să ia și să implementeze o clonă a sistemului de instruire pentru a verifica funcționarea, deoarece sistemul însuși a fost contaminat și ar afecta ubicuu orice sistem care utilizează modelul/setul de date otrăvit. Acesta a fost atacul folosit asupra clonelor din Războiul Stelelor.
Otrăvirea nedirecționată a modelului sau atacurile bizantine au loc atunci când atacatorul intenționează să reducă performanța (acuratețea) modelului și stagnează instruirea. Acest lucru ar necesita revenirea la un punct anterior compromiterii modelului/setului de date (potențial de la început).
În afară de instruirea offline, învățarea federată, o tehnică în care datele colectate de la punctele finale sunt utilizate pentru a reinstrui/îmbunătăți modelul cloud, este intrinsec vulnerabilă din cauza naturii sale descentralizate a procesării, permițând atacatorilor să participe cu dispozitive ‘endpoint’ compromise, ceea ce duce la compromiterea modelului cloud. Acest lucru ar putea avea implicații mari, deoarece același model cloud ar putea fi utilizat în milioane de dispozitive.

Figura 3: Flux de lucru TinyML de la un capăt la altul (© Renesas)
În timpul fazei de inferență, un hacker poate opta pentru tehnica de “evaziune a modelului”, prin care interoghează iterativ modelul (de exemplu, o imagine) și adaugă zgomot la intrare pentru a înțelege cum se comportă modelul. Astfel, hackerul ar putea obține o ieșire specifică/necesară, adică o decizie logică, după ce și-a ajustat intrarea de nenumărate ori fără a utiliza intrarea așteptată. O astfel de interogare ar putea fi utilizată și pentru “inversarea modelului”, în cazul în care informațiile despre model sau despre datele de instruire sunt extrase în mod similar.
Analiza riscurilor în timpul dezvoltării AI TinyML
Pentru faza de inferență, atacurile adversariale asupra modelelor de inteligență artificială reprezintă un domeniu activ de cercetare, în care mediul academic și industria s-au aliniat pentru a lucra la aceste probleme și au dezvoltat “ATLAS – Adversarial Threat Landscape for Artificial-Intelligence Systems!”, o matrice care permite analiștilor în domeniul securității cibernetice să evalueze riscul pentru modelele lor. De asemenea, este constituită din cazuri de utilizare în întreaga industrie, inclusiv ‘edge AI’. Învățând din studiile de caz furnizate, dezvoltatorii/proprietarii de produse vor înțelege modul în care le-ar putea fi afectat cazul lor de utilizare, vor evalua riscurile și vor lua măsuri de securitate suplimentare de precauție pentru a atenua îngrijorările clienților. Modelele de inteligență artificială ar trebui să fie considerate ca fiind predispuse la astfel de atacuri, iar diversele părți interesate trebuie să efectueze o evaluare atentă a riscurilor.
Pentru faza de instruire, asigurarea că seturile de date și modelele provin din surse de încredere ar reduce riscul de otrăvire a datelor/modelelor. Astfel de modele/date ar trebui să fie furnizate, de obicei, de furnizori de software de încredere. Un model ML poate fi, de asemenea, antrenat ținând cont de securitate, făcând modelul mai robust, cum ar fi o abordare bazată pe forța brută a antrenamentului adversarial, în care modelul este antrenat pe mai multe exemple adversariale și învață să se apere împotriva acestora. Cleverhans, o bibliotecă de instruire cu sursă deschisă dezvoltată de mediul academic, este utilizată pentru a construi astfel de exemple pentru atacarea, apărarea și evaluarea comparativă a unui model împotriva atacurilor adversariale. Distilarea apărării este o altă metodă prin care un model este antrenat pornind de la un model mai amplu pentru a genera probabilități de clase diferite, mai degrabă decât decizii ferme, ceea ce face mai dificilă exploatarea modelului de către adversar. Cu toate acestea, ambele metode pot fi descompuse cu o putere de calcul adecvată.
Protejați-vă IP-ul AI
 Uneori, companiile își fac griji cu privire la tentativele rău intenționate ale competitorilor de a fura proprietatea intelectuală/caracteristica modelului care este stocată pe un dispozitiv pentru care compania a alocat resurse financiare pentru cercetare și dezvoltare. Odată ce modelul este antrenat și perfecționat, acesta devine un executabil binar stocat pe microcontroler și poate fi protejat prin măsurile convenționale de securitate IoT, cum ar fi protecția interfețelor fizice ale cipului, criptarea software-ului și utilizarea TrustZone. Chiar și în cazul în care executabilul binar ar fi furat, este important de reținut că modelul final și optimizat, proiectat pentru un anumit caz de utilizare, poate fi ușor identificat și considerat ca o violare a drepturilor de autor, iar ingineria inversă ar necesita mai mult efort decât dacă s-ar porni de la zero cu un model de bază.
Uneori, companiile își fac griji cu privire la tentativele rău intenționate ale competitorilor de a fura proprietatea intelectuală/caracteristica modelului care este stocată pe un dispozitiv pentru care compania a alocat resurse financiare pentru cercetare și dezvoltare. Odată ce modelul este antrenat și perfecționat, acesta devine un executabil binar stocat pe microcontroler și poate fi protejat prin măsurile convenționale de securitate IoT, cum ar fi protecția interfețelor fizice ale cipului, criptarea software-ului și utilizarea TrustZone. Chiar și în cazul în care executabilul binar ar fi furat, este important de reținut că modelul final și optimizat, proiectat pentru un anumit caz de utilizare, poate fi ușor identificat și considerat ca o violare a drepturilor de autor, iar ingineria inversă ar necesita mai mult efort decât dacă s-ar porni de la zero cu un model de bază.
Mai mult, în dezvoltarea TinyML, modelele de inteligență artificială sunt în general bine cunoscute și sunt tehnologii cu sursă deschisă, de exemplu MobileNet, care pot fi apoi optimizate printr-o varietate de hiperparametri. Seturile de date, pe de altă parte, sunt păstrate în siguranță, deoarece sunt comori valoroase pentru care companiile cheltuiesc resurse importante pentru a le achiziționa și sunt specifice unui anumit caz de utilizare. Un exemplu ar fi adăugarea de chenare pentru regiunile de interes din imagini. Seturile de date generalizate sunt, de asemenea, disponibile ca sursă deschisă, precum CIFAR, ImageNet etc. Acestea sunt utile pentru a compara diferite modele, dar seturile de date personalizate ar trebui utilizate pentru dezvoltarea de cazuri de utilizare specifice. De exemplu, ‘visual wake word’, un set de date rezervat mediului de birou, ar oferi rezultate optime.
Rezumat
Întrucât TinyML este încă în dezvoltare, este bine să fiți conștienți de diferitele atacuri care pot apărea asupra modelelor de inteligență artificială, de felul în care acestea ar putea afecta dezvoltarea TinyML și de cazurile de utilizare specifice. În prezent, modelele ML au ajuns la o precizie ridicată, dar pentru implementare, este important să vă asigurați că modelele voastre sunt, de asemenea, robuste. În timpul dezvoltării, ambele părți (inginerii ML și inginerii din domeniul embedded) împart responsabilitatea pentru aspectele legate de securitatea cibernetică, inclusiv AI. În cazul în care inginerii ML se vor concentra pe atacurile din timpul instruirii, inginerii din sectorul embedded vor asigura protecția împotriva atacurilor de inferență.
În ceea ce privește proprietatea intelectuală a modelelor, un element crucial este să se asigure că seturile de date de instruire sunt păstrate în siguranță pentru a nu permite concurenților să dezvolte modele similare pentru cazuri de utilizare similare. Referitor la codul executabil, adică IP-ul modelului de pe dispozitiv, acesta poate fi securizat cu ajutorul celor mai bune măsuri de securitate IoT din clasa sa, pentru care familia RA de la Renesas este renumită, ceea ce face foarte dificilă accesarea în mod rău intenționat a informațiilor securizate.
Autor
Eldar Sido, Product Marketing Specialist, IoT and Infrastructure Business Unit
Renesas Electronics Europe | https://www.renesas.com
![]()
Referințe
[1] Eykholt, Kevin, et al. “Robust physical-world attacks on deep learning visual classification” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[2] Carlini, Nicholas, and David Wagner. “Audio adversarial examples: Targeted attacks on speech-to-text”. 2018 IEEE Security and Privacy Workshops (SPW). IEEE, 2018.